How LLMs Express JavaScript
Feb 16, 2026 • Filip Stankovic
I've done a lot of experiments with LLMs over the past two weeks. Each
further validated my starting hypothesis, that LLMs could be harnessed
within deterministic systems, but I could not prove why, so I kept
going.
Two days ago, I was able to get Llama-4-Maverick-17B-128E-Instruct-FP8
to express, unironically, that the sky was red by modifying a background
style to red. I was also able to get Gemini 3 Pro to parse a 100mb
JavaScript file in the middle of a chat and not blink an eye. This was
done by overloading the context window with compiled JavaScript, then
providing additional instructions.
Completion Token Distribution: Asking Llama To "Make Sky Red"
200
400
600
800
1400+
Input Prompt Tokens (ea.): 92405, Unique Token Counts: 147, Attempts:
~400
In every single run, Llama-4 updated an index.html background to be red
or amber. Three things of note: (1) this is a math model, not a
reasoning model (as we know it), (2) the ratio of input tokens to
completion tokens and (3) the tiny number of completion tokens.
More serious results and analysis below.
A Final Experiment
The prompt starts with a large amount of compiled JavaScript code. In my
latest prompt, I used Facebook front-end compiled JavaScript binaries,
though my own compiled code worked just as well before. These files are
meaningless to humans, example below.
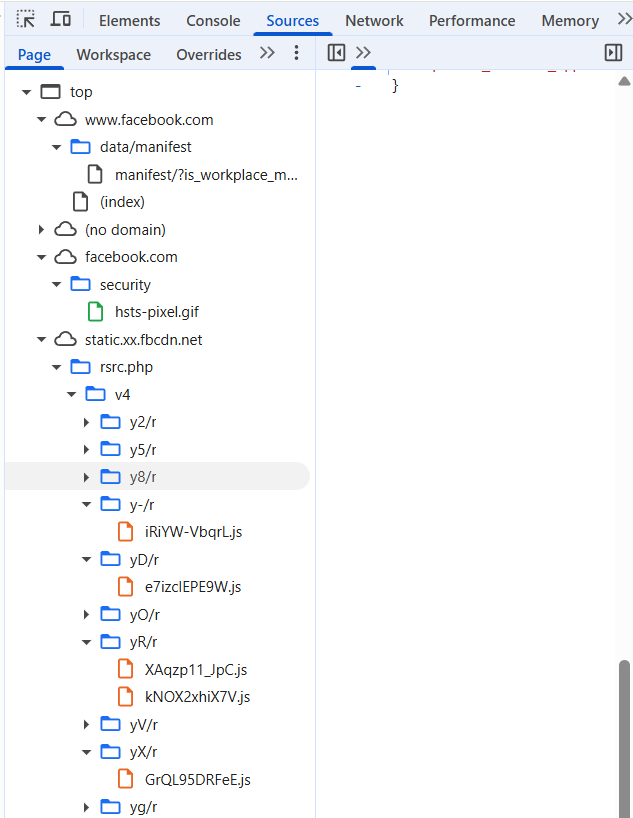
Example: Facebook Static Compiled Binaries
Input Prompt:
-
FB-Static Folder: 37 JavaScript binaries / chunks from
Facebook.
-
Initial App Source: a folder with ~8 code files containing
front-end state, back-end state and mock data.
-
"Consulting Strategy Brief": two abstract paragraphs
templated with small amounts of client data injected into it to
generate unique code per customer.
Results
I ran this prompt against two LLM APIs: Gemini-3-Flash-Preview (Google)
and Llama-4-Maverick-17B-128E-Instruct-FP8 (Together API), with 10
variations of the strategy brief (different customer data), and a few
times for each model.
See the full db-run-1 output file,
including all token counts and response times.
I asked Gemini-Flash to analyize this 50mb JavaScript file for me:
An LLM Thinking In JavaScript
You can see the results in the chart below, done in one-shot.
It also rendered everything else you see here, and helped me make minor
edits, always returning perfectly semantic code. This is similar to how
we have come to expect it to help us edit our English texts. Except this
page is not English, it is code.
Seeing Is Beliving
2
This sounds crazy, but: when giving LLM initial context
like this, it is able to conceptualize JavaScript (math), in an abstract
way. It solves problems inputted as prompts with abstract paths that we
have never seen before. It is effectively representing math the way that
we do language, as a top-down and abstract function.
Sometimes it helps to see a negative case.
Here I forgot
to include FB-Static binaries in my prompt, which I fixed in
the next one.
You can validate my statement above with a single prompt. The fastest
way to do that is to click one of the chats above and ask the model to
do something. It will do it in a way that you have never seen before.
Theory
Below are theories that I drafted on Friday that may help frame this. I
have not proofread or re-visited since then, but they should help get
you there, given you have the right foundational knowledge on LLMs and
Transformers.
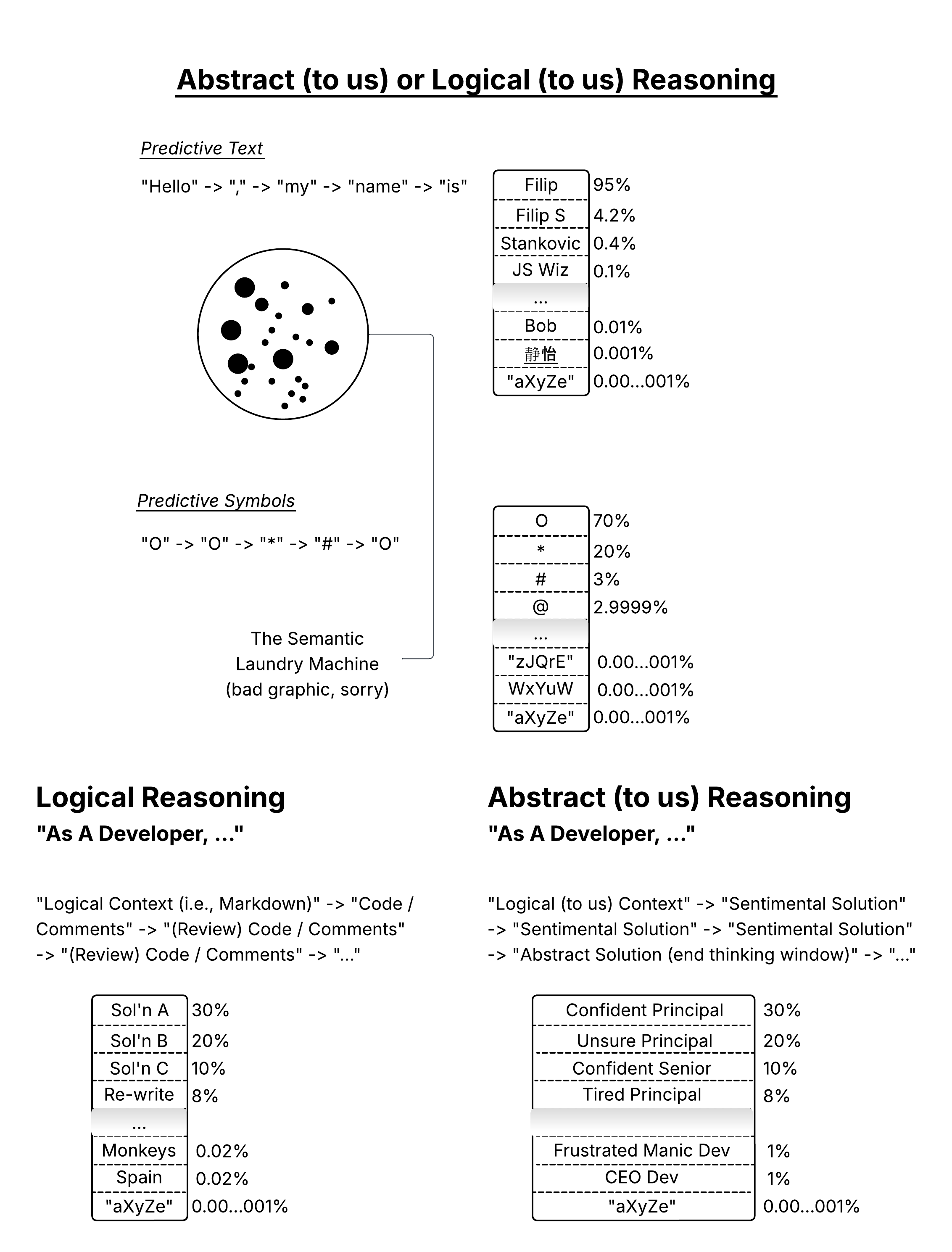
Abstract vs Logical Reasoning
Groupthink And How Big SPAs Work
If LLMs have learned how to produce abstract static media binaries
(images, video, etc.) through transformer training, then why not
JavaScript? The data is abundant, and appears to be just as relevant,
when considering the training methodology.
All code is on
GitHub and MIT-licensed.
Be forewarned, it looks more like a custom NodeJS Jupyter notebook than
an app at this point.
Feedback welcome. Thank you,
Filip